
Extract, Load, and Transform (ELT)
ELT workflows differ from ETL workflows solely in where the data transformation takes place. Instead of a separate transformation engine, the destination data store is used to load and transform data. This simplifies the design by removing extraneous components that would typically be used to transform data. Since the transformation and load components are one and the same, the destination data store must be powerful enough to efficiently complete both tasks at the same time. This makes large-scale analytics scenarios the perfect use cases for ELT workflows since they rely on the scalability of MPP technologies such as Azure Synapse Analytics or Azure Databricks. Figure 1.16 illustrates the common Azure technologies used in each phase of an ELT workflow.
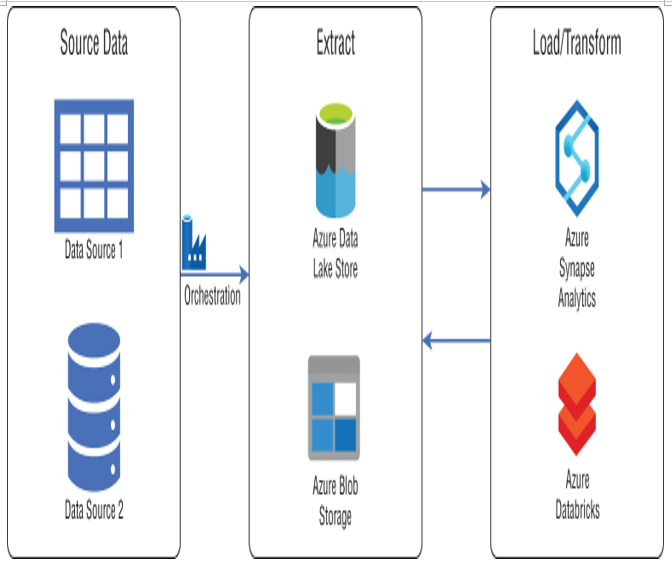
FIGURE 1.16 ELT workflow
In this example, data is extracted from its source systems via ADF and stored as flat files in a raw data store such as ADLS or Azure Blob Storage. Next, data is virtually “loaded” into staging tables in the destination data store. Data virtualization is what enables ELT workflows to process massive amounts of data with relatively little overhead. Instead of data being physically stored in the destination data store, external tables are used to overlay a schema over the flat file data in ADLS or Azure Blob Storage. The data is then able to be queried like any other table, without taking up storage in the destination data store. MPP technologies such as Spark (using Azure Databricks or Azure Synapse Apache Spark pools) and Azure Synapse Analytics are typical data stores used for this approach because they have mechanisms for creating external tables and performing transformations on them. The following sections will describe each phase in further detail.
Extract
Collecting data from various sources is just as important in ELT workflows as it is in ETL. Unlike with ETL scenarios that might begin raw processing once the data is extracted, data involved in ELT scenarios is always consolidated in a central repository. These repositories must be able to handle large volumes of data. Scalable file systems that are based on the Hadoop Distributed File System (HDFS), such as ADLS and Azure Blob Storage, are typically used in these scenarios.Extracted data must also be in formats that are compatible with the loading mechanisms of the destination technology. Typical file formats include delimited text files, such as CSV or TSV, semi-structured files such as XML or JSON, and column compressed files such as AVRO, ORC, or Parquet. Column compressed file formats should be used for larger datasets as these are optimized for big data workloads because they support very efficient compression and encoding schemes. Parquet is widely used because of its ability to embed the data’s schema within the structure of the data, thus reducing the complexity of data loading and transformation logic.
Leave a Reply