
Control Flows and Data Flows
Many ETL tools employ two methods for orchestrating data pipelines. Tasks that ensure the orderly processing of data processing activities are known as control flows. Data processing activities are referred to as data flows and can be executed in sequence from a control flow. Data engineers that use ADF to orchestrate their data pipelines can use control flows to manage the processing sequence of their data flows.
Control flows are used to enforce the correct processing order of data movement and data transformation activities. Using precedence constraints, control flows can dictate how pipelines proceed if a task succeeds or fails. Subsequent tasks do not begin processing until their predecessors complete. Examples of control flow operations in ADF include Filter, ForEach, If Condition, Set Variable, Until, Web, and Wait activities. ADF also allows engineers to run entire pipelines within a pipeline after an activity has finished with the Execute Pipeline control flow activity. Figure 1.12 shows a simple control flow in ADF, where the Lookup task is retrieving table metadata from a SQL Server database that will be passed to a set of Copy activities to migrate those tables to a data warehouse hosted in Azure Synapse Analytics.
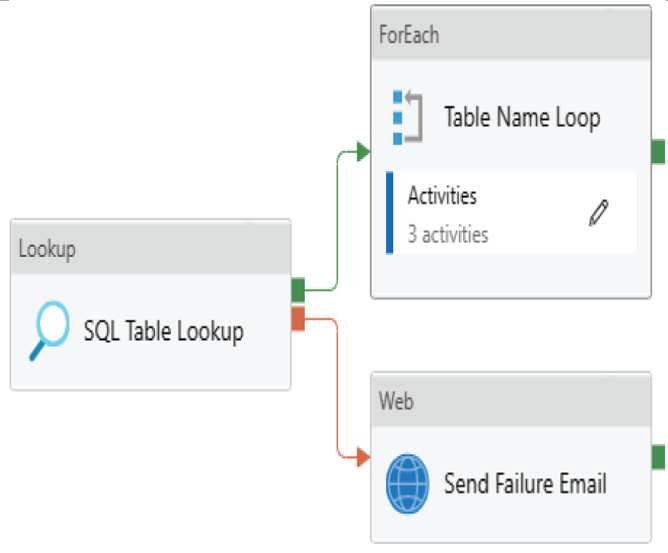
FIGURE 1.12 ADF control flow
This control flow includes outcomes for successful lookups of table metadata and failures. If metadata is retrieved successfully, then the next step will be a ForEach loop that includes data movement tasks that will migrate each SQL Server table successfully retrieved to Azure Synapse Analytics. If the Lookup task fails for whatever reason, then the next step will be a Web activity that will send an email alerting an administrator of the failure.
Another example of a control flow is the order in which different mapping data flows are executed. Using the Data Flow activity, data engineers can chain together multiple mapping data flows to process data in the correct order. Figure 1.13 illustrates an example of a control flow that executes a series of data flows sequentially and in parallel.
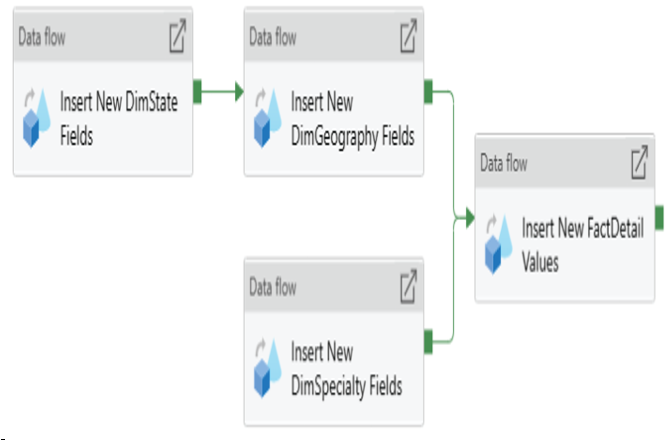
FIGURE 1.13 Ordering data flow processing with a control flow
This pipeline begins by inserting new State fields followed by new geography fields in the State and geography destination tables, all the while inserting new specialty fields in parallel. Once these data flows are complete, the control flow will run a final data flow that inserts new detail fields into the destination detail table. Of course, these tasks only control what order ETL activities run in, not the underlying data transformation steps. ADF allows developers to build or edit specific mapping data flows by double-clicking their corresponding Data Flow control flow activity.
While control flows manage the order of operations for ETL pipelines, data flows are where the ETL magic happens. Data flows are specific tasks in a control flow and are responsible for extracting data from its source, transforming it, and loading the transformed data into the appropriate destination data stores. The output of one data flow task can be the input to the next one, and data flows without a dependency on each other can run in parallel. As mentioned in the section “Transform” earlier in this chapter, ADF can execute four types of transformation activities that can serve as data flows. This section will focus on two of those types: mapping data flows and external compute services that host custom code.
Mapping data flows are ETL pipelines that data engineers can design with a GUI. Developers begin by selecting a source to extract data from, then performing one or more transformation activities on the data, and finally loading the transformed data into a destination data store. The finished data flows are translated to code upon execution and use scaled-out Apache Spark clusters to run them. Figure 1.14 is a screenshot of the Insert New DimSpecialty fields data flow task from Figure 1.13.
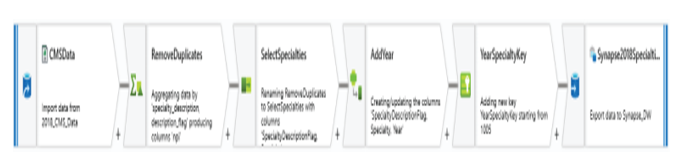
FIGURE 1.14 ADF mapping data flow
This data flow begins by extracting data from a CSV file. Next, the CSV data undergoes a few transformations including the removal of duplicate rows, selecting only the columns needed, and creating new columns to conform to the destination data store’s schema. Finally, the data flow loads the transformed data to the DimSpecialty table in Azure Synapse Analytics by inserting each transformed column into its associated destination column. Once these tasks are completed, the control flow will flag this data flow as being successfully completed and wait on the Insert New DimGeography Fields data flow to successfully complete before moving on to the Insert New FactDetail Values data flow.
ADF can also be used to automate custom-coded data flow activities that are hosted in external compute services such as Azure Functions, Azure Databricks, SQL Stored Procedures, or Azure HDInsight. Code hosted on these platforms can be used to perform one or more phases of an ETL pipeline. Running these tasks as activities in ADF allows them to run on a scheduled basis and alongside other activities such as mapping data flows or other custom-coded data flows. Figure 1.15 illustrates a control flow in ADF that executes external data flows that are hosted in Azure Databricks and Azure SQL Database.
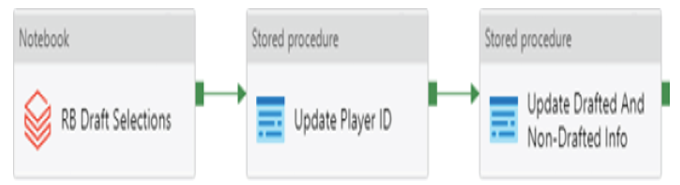
FIGURE 1.15 Azure Databricks and SQL stored procedure control flow
This example is a part of a solution that analyzes American football players who are NFL football players. The destination data store is a data warehouse hosted on an Azure SQL Database that provides consumers with the ability to compare the current year’s group of prospects with those in previous years. The pipeline in Figure 1.15 starts by running a Python notebook hosted in Azure Databricks that extracts information on when a prospect was selected in the current year’s NFL Draft, cleanses the data, and loads the cleansed data in the data warehouse. The next step in the pipeline is to run a stored procedure in the data warehouse that associates a unique identifier that was assigned to them before the NFL draft. Finally, the pipeline executes another stored procedure that tells analysts if a prospect was not drafted. As you can see, each of these data flows is critical to the success of this data analytics solution. ADF makes it possible to run these activities that are developed on different technologies in sequential order and control when they should run.
Leave a Reply