
Analytical Workload Design Considerations
Data warehouses and online analytical processing (OLAP) systems are optimally designed for read-heavy applications. While OLTP systems focus on storing current transactions, data warehouses and OLAP models focus on storing historical data that can be used to measure a business’s performance and predict what future actions it should take.
Data warehouses serve as central repositories of data from one or more disparate data sources, including various OLTP systems. Not only does this eliminate the burden of running analytical workloads from the OLTP database, it also enriches the OLTP data with other data sources that provide useful information for decision makers. Data warehouses can store data that is processed in batch and in real time to provide a single source of truth for an organization’s analytical needs. Data analysts commonly run analytical queries against data warehouses that return aggregated calculations that can be used to support business decisions.
Data warehouses can be built using one of the SMP database offerings on Azure, such as Azure SQL Database, or on the MPP data warehouse Azure Synapse Analytics dedicated SQL pools. The choice largely depends on the amount of historical data that is going to be stored and the nature of the queries that will be issued to the data warehouse. A good rule of thumb is that if the size of the data warehouse is going to be less than 1 terabyte, then Azure SQL Database will do the trick. However, this is a general statement, and more consideration is needed when deciding between SMP or MPP. Chapter 5, “Modern Data Warehouses in Azure,” covers more detail on what to consider when designing a modern data warehouse.
OLAP models extract commonly used data for reporting from data warehouses to simplify data analysis. Like data warehouses, OLAP models are used for read-heavy scenarios and typically include the following predefined features to allow users to see consistent results without having to write their own logic:
- Aggregations that can be immediately reported against
- Time-oriented calculations
OLAP models come in two flavors: multidimensional and tabular. Multidimensional cubes such as those created with SQL Server Analysis Services (SSAS) were used in traditional business intelligence (BI) solutions to serve data as dimensions and measures. Tabular models such as Azure Analysis Services and models built in Power BI serve data using relational modeling constructs (e.g., tables and columns) while storing metadata as multidimensional modeling constructs (e.g., dimensions and measures) behind the scenes. Tabular models have become the standard for OLAP models as they use similar design patterns to relational databases, make use of columnar storage that optimally compresses data for analytics and leverages an easy-to-learn language (DAX) that data analysts can use to create custom metrics. Chapter 6, “Reporting with Power BI,” will describe in detail tabular models and how they are used in Power BI.
Data warehouses and OLAP models store data in a way that is designed to be easy for analysts and developers to read. Tables in analytical systems are defined to be easily understood by business users so that they do not have to rely on IT every time they need to produce new analysis against historical data. Instead of using strict nomenclature and normalized rules that make OLTP systems ideal for storing transactional data, analytical systems flatten data so that business users can easily query data without having to join several tables together.
One common design pattern for data warehouses and OLAP models is the star schema. Star schemas denormalize data taken from OLTP systems, resulting in some attributes being duplicated in tables. This is done to make the data easier for analysts to read, allowing them to avoid having to join several tables in their queries. While de-normalization is not optimal for write-heavy, transactional workloads, it will increase the performance of read-oriented, analytical workloads.
Star schemas work by relating business entities, also known as the nouns of the business, to measurable events. These can be broken down into the following classifications that are specific to a star schema:
- Dimension tables store information about business entities. Dimension tables store descriptive columns for each entity and a key column that serves as a unique identifier. Examples include date, customer, geography, and product dimensions. Dimension tables typically store a relatively small number of rows but many columns, depending on how many descriptors are necessary for a given dimension.
- Fact tables store measurable observations or events such as Internet sales, inventory, or sales quotas. Along with numeric measurements, fact tables contain dimension key columns for each dimension that a measure or observation is related to. These relationships determine the granularity of the data in the fact table. For example, an Internet sales fact table that has a dimension key for date is only as granular as the level of detail stored in the date dimension table. If the date dimension table only includes details for years and months, then queries performing time-based calculations will only be able to drill down to monthly sales. However, if it includes details for years, quarters, months, weeks, days, and hours, then queries will be able to perform more fine-grained analysis of the data.
Figure 2.2 is a partial example of the AdventureWorks DW star schema, focusing on dimensions and facts related to Internet sales for products manufactured and sold by AdventureWorks. The entire diagram can be found at https://dataedo.com/samples/html/Data_warehouse/doc/AdventureWorksDW_4/modules/Internet_Sales_101/module.html.
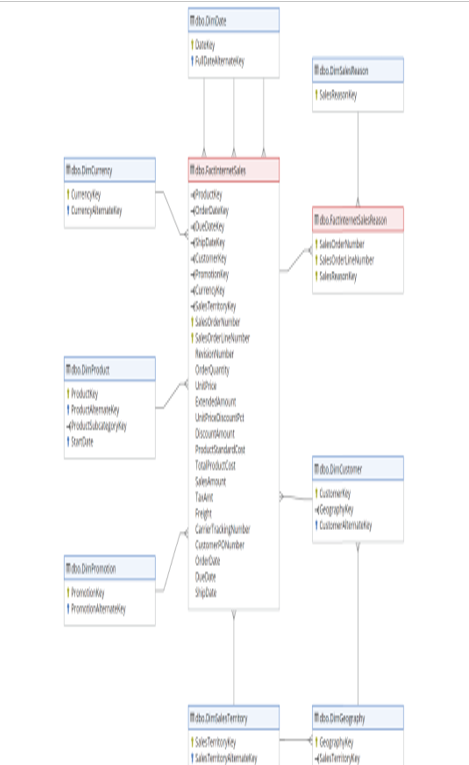
FIGURE 2.2 Star schema
This diagram shows the relationship between the nouns involved in an online sale and the associated metrics. While not illustrated in the image, if you go to the link in the preceding paragraph, you will find more details on each dimension table and will see that they have many columns that provide high granularity for the sales metrics.
OLAP models take star schemas a step further by including business logic and predefined calculations that are ready to be used in reports. This level of abstraction that allows users to focus on building business-critical reports without needing to write SQL queries that perform aggregations and joins over the underlying data is known as a semantic layer. Semantic layers are typically placed over data pulled from a data warehouse. Along with the business-friendly names that come with a star schema, semantic layers store calculations that allow users to easily filter and summarize data.
Leave a Reply